Slurm Power Saving Guide
Contents
- Overview
- Configuration
- Node Lifecycle
- Manual Power Saving
- Resume and Suspend Programs
- Fault Tolerance
- Booting Different Images
- Use of Allocations
- Node Features
- Hybrid Cluster
- Cloud Accounting
Overview
Slurm provides an integrated mechanism for nodes being suspended (powered down, placed into power saving mode) and resumed (powered up, restored from power saving mode) on demand or by request. When automatic power saving is enabled, nodes that remain IDLE for SuspendTime are suspended by SuspendProgram, and nodes needed to complete work allocated to them are resumed by ResumeProgram. Nodes suspended by SuspendProgram will be unavailable for scheduling for SuspendTimeout without manual intervention. Nodes resumed by ResumeProgram must register within ResumeTimeout or they will become DOWN and their allocated jobs are requeued. The rate of nodes being resumed or suspended can be controlled by ResumeRate and SuspendRate.
Slurm can be configured to accomplish power saving by managing compute resources in any cloud provider (e.g. Amazon Web Services, Google Cloud Platform, Microsoft Azure) via their API. These resources can be combined with an existing cluster to process excess workload (cloud bursting) or it can operate as an independent and self-contained cluster.
To enable automatic Power Saving operations in Slurm, you must configure the following. These programs, timeouts, and rates are not required for manual power saving operations.
- ResumeProgram and SuspendProgram must be defined. Each must be either a valid path to a program or the name of a PowerAction defined in slurm.conf.
- ResumeTimeout and SuspendTimeout must be defined, either globally or on at least one partition.
- SuspendTime must be defined, either globally, on at least one partition, or on at least one node, and not be INFINITE or -1.
- ResumeRate and SuspendRate must be greater than or equal to 0.
Changes in the configuration parameters (e.g. SuspendTime) will take
effect after modifying the slurm.conf configuration file and executing
scontrol reconfigure or restarting the Slurm control daemon,
slurmctld.
Configuration
The following configuration parameters of interest include:
- DebugFlags
-
Defines specific subsystems which should provide more detailed event logging. Options of interest include:
- PowerAction
-
Defines a named power management program, including the location where it runs. Once defined, a PowerAction's name can be used in place of a program path for ResumeProgram, ResumeFailProgram, or SuspendProgram. A specific PowerAction can also be selected for an individual request with the
Action=<name>option toscontrol power up|down(see Manual Power Saving).PowerAction is also supported for reboot operations, but those are outside the scope of this guide.
PowerAction=<name> Location=<slurmctld|slurmd> Program="<path> [arguments...]"
- PowerAction=<name>
Unique name for the action.
- Location=slurmctld|slurmd
Where the program will run. slurmctld runs the program on the controller as SlurmUser; slurmd runs the program on each affected compute node as SlurmdUser. Power up actions must use slurmctld, since powered down nodes cannot run a slurmd action.
- Program=<path>
Program to be executed. Arguments may be included in this field. If arguments are included, quote the complete Program value in slurm.conf. The program must be accessible and executable by the user appropriate for the configured Location. The first whitespace-separated token is used as the executable path; any remaining tokens are passed as arguments before the arguments added by Slurm.
Slurm appends action-specific arguments after any arguments configured in Program:
Operation Location=slurmctld Location=slurmd Power Up (ResumeProgram) Runs with the affected nodes as a hostlist argument. Not valid for power up actions. Power Down (SuspendProgram) Runs with the affected nodes as a hostlist argument. Runs once per affected node. The local node name is passed as an argument and is also available in the environment as SLURM_NODE_NAME. Example:
PowerAction=cloud_resume Location=slurmctld Program=/usr/sbin/slurm_resume PowerAction=node_suspend Location=slurmd Program="/usr/sbin/shutdown -h now" ResumeProgram=cloud_resume SuspendProgram=node_suspend
- ReconfigFlags
-
Flags to control various actions that may be taken when an
scontrol reconfigurecommand is issued. Options of interest include: - ResumeFailProgram
-
Program to be executed when nodes fail to resume by ResumeTimeout. The argument to the program will be the names of the failed nodes (using Slurm's hostlist expression format). This can alternatively be set to the name of a PowerAction.
- ResumeProgram
-
Program to be executed to restore nodes from power saving mode. The program executes as SlurmUser (as configured in slurm.conf). The argument to the program will be the names of nodes to be restored from power savings mode (using Slurm's hostlist expression format). This can alternatively be set to the name of a PowerAction.
If the slurmd daemon fails to respond within the configured ResumeTimeout value with an updated BootTime, the node will be placed in a DOWN state and the job requesting the node will be requeued. If the node isn't actually rebooted (e.g. when multiple-slurmd is configured) you can start slurmd with the "-b" option to report the node boot time as now.
A job to node mapping is available in JSON format by reading the temporary file specified by the SLURM_RESUME_FILE environment variable. This file should be used at the beginning of ResumeProgram - see the Fault Tolerance section for more details. This program may use the
scontrol show nodenamecommand to ensure that a node has booted and the slurmd daemon started.SLURM_RESUME_FILE=/proc/1647372/fd/7: { "all_nodes_resume" : "cloud[1-3,7-8]", "jobs" : [ { "exclusive" : "NO", "extra" : "An arbitrary string from --extra", "features" : "c1,c2", "job_id" : 140814, "nodes_alloc" : "cloud[1-4]", "nodes_resume" : "cloud[1-3]", "oversubscribe" : "OK", "partition" : "cloud", "reservation" : "resv_1234" }, { "exclusive" : "NO", "extra" : null, "features" : "c1,c2", "job_id" : 140815, "nodes_alloc" : "cloud[1-2]", "nodes_resume" : "cloud[1-2]", "oversubscribe" : "OK", "partition" : "cloud", "reservation" : null }, { "exclusive" : "NODE", "extra" : null, "features" : null, "job_id" : 140816, "nodes_alloc" : "cloud[7-8]", "nodes_resume" : "cloud[7-8]", "oversubscribe" : "NO", "partition" : "cloud_exclusive", "reservation" : null } ] }oversubscribe is NO, YES, or OK; exclusive is NO, NODE, USER, MCS, or TOPO (same meanings as squeue --format
%hand squeue --Format Exclusive. See alsoSLURM_JOB_OVERSUBSCRIBEandSLURM_JOB_EXCLUSIVEin prolog_epilog.NOTE: The SLURM_RESUME_FILE will only exist and be usable if Slurm was compiled with the JSON-C serializer library.
- ResumeRate
-
Maximum number of nodes to be removed from power saving mode per minute. A value of zero results in no limits being imposed. The default value is 300. Use this to prevent rapid increases in power consumption.
- ResumeTimeout
-
Maximum time permitted (in seconds) between when a node resume request is issued and when the node is actually available for use. Nodes which fail to respond in this time frame will be marked DOWN and the jobs scheduled on the node requeued. Nodes which reboot after this time frame will be marked DOWN with a reason of "Node unexpectedly rebooted." The default value is 60 seconds.
- SchedulerParameters
-
The interpretation of this parameter varies by SchedulerType. Multiple options may be comma separated. Options of interest include:
- salloc_wait_nodes
-
If defined, the salloc command will wait until all allocated nodes are ready for use (i.e. booted) before the command returns. By default, salloc will return as soon as the resource allocation has been made. The salloc command can use the
--wait-all-nodesoption to override this configuration parameter. - sbatch_wait_nodes
-
If defined, the sbatch script will wait until all allocated nodes are ready for use (i.e. booted) before the initiation. By default, the sbatch script will be initiated as soon as the first node in the job allocation is ready. The sbatch command can use the
--wait-all-nodesoption to override this configuration parameter.
- SlurmctldParameters
-
Comma-separated options identifying slurmctld options. Options of interest include:
- cloud_dns
-
By default, Slurm expects that the network addresses for cloud nodes won't be known until creation of the node and that Slurm will be notified of the node's address upon registration. Since Slurm communications rely on the node configuration found in the slurm.conf, Slurm will tell the client command, after waiting for all nodes to boot, each node's IP address. However, in environments where the nodes are in DNS, this step can be avoided by configuring this option.
- idle_on_node_suspend
-
Mark nodes as idle, regardless of current state, when suspending nodes with SuspendProgram so that nodes will be eligible to be resumed at a later time.
- node_reg_mem_percent=#
-
Percentage of memory a node is allowed to register with without being marked as invalid with low memory. Default is 100. For State=CLOUD nodes, the default is 90.
- power_save_interval=#
-
How often the power_save thread looks to resume and suspend nodes. The power_save thread will do work sooner if there are node state changes. Default is 10 seconds.
- power_save_min_interval=#
-
How often the power_save thread, at a minimum, looks to resume and suspend nodes. Default is 0.
- SuspendExcNodes
-
Nodes not subject to suspend/resume logic. This may be used to avoid suspending and resuming nodes which are not in the cloud. Alternately the suspend/resume programs can treat local nodes differently from nodes being provisioned from cloud. Use Slurm's hostlist expression to identify nodes with an optional ":" separator and count of nodes to exclude from the preceding range. For example
nid[10-20]:4will prevent 4 usable nodes (i.e IDLE and not DOWN, DRAINING or already powered down) in the setnid[10-20]from being powered down. Multiple sets of nodes can be specified with or without counts in a comma separated list (e.gnid[10-20]:4,nid[80-90]:2). By default, no nodes are excluded. This value may be updated with scontrol. See ReconfigFlags=KeepPowerSaveSettings for setting persistence. - SuspendExcParts
-
List of partitions with nodes to never place in power saving mode. Multiple partitions may be specified using a comma separator. By default, no nodes are excluded. This value may be updated with scontrol. See ReconfigFlags=KeepPowerSaveSettings for setting persistence.
- SuspendExcStates
-
Specifies node states that are not to be powered down automatically. Valid states include CLOUD, DOWN, DRAIN, DYNAMIC_FUTURE, DYNAMIC_NORM, FAIL, INVALID_REG, MAINTENANCE, NOT_RESPONDING, PERFCTRS, PLANNED, and RESERVED. By default, any of these states, if idle for SuspendTime, would be powered down. This value may be updated with scontrol. See ReconfigFlags=KeepPowerSaveSettings for setting persistence.
- SuspendProgram
-
Program to be executed to place nodes into power saving mode. The program executes as SlurmUser (as configured in slurm.conf). The argument to the program will be the names of nodes to be placed into power savings mode (using Slurm's hostlist expression format). This can alternatively be set to the name of a PowerAction.
- SuspendRate
-
Maximum number of nodes to be placed into power saving mode per minute. A value of zero results in no limits being imposed. The default value is 60. Use this to prevent rapid drops in power consumption.
- SuspendTime
-
Nodes becomes eligible for power saving mode after being idle or down for this number of seconds. A negative number disables power saving mode. The default value is -1 (disabled).
- SuspendTimeout
-
Maximum time permitted (in second) between when a node suspend request is issued and when the node shutdown is complete. At that time the node must ready for a resume request to be issued as needed for new workload. The default value is 30 seconds.
Node Configuration
Node parameters of interest include:
- Feature
-
A node feature can be associated with resources acquired from the cloud and user jobs can specify their preference for resource use with the
--constraintoption. - NodeName
-
This is the name by which Slurm refers to the node. A name containing a numeric suffix is recommended for convenience.
- State
-
Nodes which are to be added on demand should have a state of CLOUD.
- SuspendTime
-
Nodes which remain idle or down for this number of seconds will be placed into power saving mode by SuspendProgram.
This value takes precedence over the partition-level and global SuspendTime settings for the specified nodes. If not set on the node, the partition and then global values are used. Setting SuspendTime to INFINITE will disable suspending of these nodes.
- Weight
-
Each node can be configured with a weight indicating the desirability of using that resource. Nodes with lower weights are used before those with higher weights. The default value is 1. Slurm will allocate from powered up nodes first, powering up nodes second and lastly powered down nodes -- respecting node weights in each set.
Partition Configuration
Partition parameters of interest include:
- PowerDownOnIdle
-
If set to YES and power saving is enabled for the partition, then nodes allocated from this partition will be requested to power down after being allocated at least one job. These nodes will not power down until they transition from COMPLETING to IDLE. If set to NO then power saving will operate as configured for the partition. The default value is NO.
The following will cause a transition from COMPLETING to IDLE:
- Completing all running jobs without additional jobs being allocated.
- Exclusive=USER and after all running jobs complete but before another user's job is allocated.
- Exclusive=NODE and after the running job completes but before another job is allocated.
NOTE: Nodes are still subject to powering down when being IDLE for SuspendTime when PowerDownOnIdle is set to NO.
- ResumeTimeout
-
Maximum time permitted (in seconds) between when a node resume request is issued and when the node is actually available for use. Nodes which fail to respond in this time frame will be marked DOWN and the jobs scheduled on the node requeued. Nodes which reboot after this time frame will be marked DOWN with a reason of "Node unexpectedly rebooted." The default value is 60 seconds.
For nodes that are in multiple partitions with this option set, the highest time will take effect. If not set on any partition, the node will use the ResumeTimeout value set for the entire cluster.
- SuspendTime
-
Nodes which remain idle or down for this number of seconds will be placed into power saving mode by SuspendProgram.
For nodes that are in multiple partitions with this option set, the highest time will take effect. If not set on any partition, the node will use the SuspendTime value set for the entire cluster. A SuspendTime value set on a NodeName line takes precedence over this partition-level value. Setting SuspendTime to INFINITE will disable suspending of nodes in this partition.
- SuspendTimeout
-
Maximum time permitted (in second) between when a node suspend request is issued and when the node shutdown is complete. At that time the node must ready for a resume request to be issued as needed for new workload. The default value is 30 seconds.
For nodes that are in multiple partitions with this option set, the highest time will take effect. If not set on any partition, the node will use the SuspendTimeout value set for the entire cluster.
Node Lifecycle
When Slurm is configured for Power Saving operation, nodes have an
expanded set of states associated with them. States associated with Power
Saving are generally labeled with a symbol when viewing node details with
sinfo.
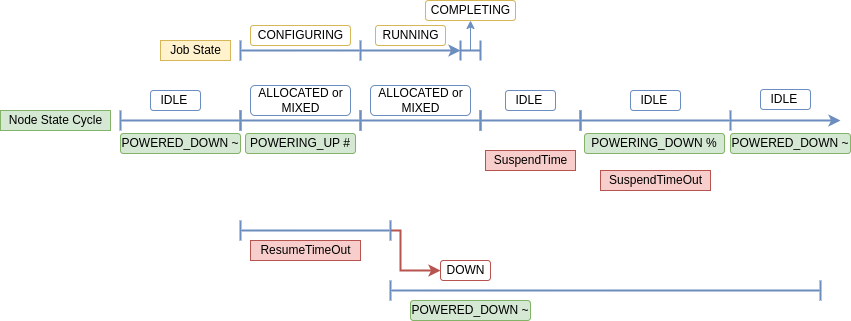
Figure 1. Node Lifecycle
Node states of interest:
| STATE | Power Saving Symbol | Description |
| POWER_DOWN | ! | Power down request. When the node is no longer running job(s), run the SuspendProgram. |
| POWER_UP | Power up request. When possible, run the ResumeProgram. | |
| POWERED_DOWN | ~ | The node is powered down or in power saving mode. |
| POWERING_DOWN | % | The node is in the process of powering down, or being put into power saving mode, and is not capable of running any jobs for SuspendTimeout. |
| POWERING_UP | # | The node is in the process of powering up, or being restored from power saving mode. |
Manual Power Saving
A node can be manually powered up and down by setting the state of the node
to the following states using scontrol:
scontrol update nodename=<nodename> state=power_<down|down_asap|down_force|up>
The equivalent scontrol power subcommand can also be used.
It supports selecting a configured
PowerAction for the request instead of the
default ResumeProgram or SuspendProgram:
scontrol power <up|down> [asap|force] {ALL|<nodelist>|<nodeset>} [Action=<name>]
[Reason=<reason>]
NOTE: Reason= is only accepted for
power down.
scontrol update command actions/states of interest:
- POWER_DOWN
- Will use the configured SuspendProgram program to explicitly place a node in power saving mode. If a node is already in the process of being powered down, the command will only change the state of the node but won't have any effect until the configured SuspendTimeout is reached.
- POWER_DOWN_ASAP
- Will drain the node and mark it for power down. Currently running jobs will complete first and no additional jobs will be allocated to the node.
- POWER_DOWN_FORCE
- Will cancel all jobs on the node, power it down, and reset its state to IDLE.
- POWER_UP
- Will use the configured ResumeProgram program to explicitly move a node out of power saving mode. If a node is already in the process of being powered up, the command will only change the state of the node but won't have any effect until the configured ResumeTimeout is reached.
- RESUME
- Not an actual node state, but will change a node state from DRAIN, DRAINING, DOWN or REBOOT to IDLE and NoResp. slurmctld will then attempt to contact slurmd to request that the node register itself. Once registered, the node state will then remove the NoResp flag and will resume normal operations. It will also clear the POWERING_DOWN state of a node and make it eligible to be allocated.
Resume and Suspend Programs
When ResumeProgram or SuspendProgram is set to a filesystem
path, that program executes as SlurmUser on the host where the
slurmctld daemon runs (primary and backup controller nodes). When either
parameter names a PowerAction instead, the
Location field determines what user runs the program where, as explained
above. The commands used to change power state will depend upon your cluster
management tools and may require sudo for the executing user to run.
If you need to convert Slurm's hostlist expression into individual node names,
the scontrol show hostnames command may prove useful.
The ResumeProgram and SuspendProgram are not subject to any time limits but must have Fault Tolerance. They should perform the required action, ideally verify the action (e.g. node boot and start the slurmd daemon, thus the node is no longer non-responsive to slurmctld) and terminate. Long running programs will be logged by slurmctld, but not aborted.
Example ResumeProgram:
#!/bin/bash
# Example ResumeProgram
hosts=$(scontrol show hostnames "$1")
logfile=/var/log/power_save.log
echo "$(date) Resume invoked $0 $*" >>$logfile
for host in $hosts
do
sudo node_startup "$host"
done
exit 0
Example SuspendProgram:
#!/bin/bash
# Example SuspendProgram
hosts=$(scontrol show hostnames "$1")
logfile=/var/log/power_save.log
echo "$(date) Suspend invoked $0 $*" >>$logfile
for host in $hosts
do
sudo node_shutdown "$host"
done
exit 0
NOTE: the stderr and stdout of the suspend and resume programs are not logged. If logging is desired, then it should be added to the scripts.
Fault Tolerance
If the slurmctld daemon is terminated gracefully, it will wait up to ten seconds (or the maximum of SuspendTimeout or ResumeTimeout if less than ten seconds) for any spawned SuspendProgram or ResumeProgram to terminate before the daemon terminates. If the spawned program does not terminate within that time period, the event will be logged and slurmctld will exit in order to permit another slurmctld daemon to be initiated. Any spawned SuspendProgram or ResumeProgram will continue to run.
When the slurmctld daemon shuts down, any SLURM_RESUME_FILE temporary files are no longer available, even once slurmctld restarts. Therefore, ResumeProgram should use SLURM_RESUME_FILE within ten seconds of starting to guarantee that it still exists.
Booting Different Images
If you want ResumeProgram to boot various images according to job specifications, it will need to be a fairly sophisticated program and perform the following actions:
- Determine which jobs are associated with the nodes to be booted. SLURM_RESUME_FILE will help with this step.
- Determine which image is required for each job. Images can be mapped with NodeFeaturesPlugins.
- Boot the appropriate image for each node.
Use of Allocations
A resource allocation request will be granted as soon as resources are selected for use, possibly before the nodes are all available for use. The launching of job steps will be delayed until the required nodes have been restored to service (it prints a warning about waiting for nodes to become available and periodically retries until they are available).
In the case of an sbatch command, the batch program will start when
node zero of the allocation is ready for use and pre-processing can be
performed as needed before using srun to launch job steps. The
sbatch --wait-all-nodes=<value> option can be used
to override this behavior on a per-job basis and a system-wide default can be
set with the SchedulerParameters=sbatch_wait_nodes option.
In the case of the salloc command, once the allocation is made a
new shell will be created on the login node. The salloc
--wait-all-nodes=<value> option can be used to override
this behavior on a per-job basis and a system-wide default can be set with
the SchedulerParameters=salloc_wait_nodes option.
Node Features
Features defined by NodeFeaturesPlugins, and associated to cloud nodes in the slurm.conf, will be available but not active when the node is powered down. If a job requests available but not active features, the controller will allocate nodes that are powered down and have the features as available. At allocation, the features will be made active. A cloud node will remain with the active features until the node is powered down (i.e. the node can't be rebooted to get other features until the node is powered down). When the node is powered down, the those features become available but not active. Any feature not defined by NodeFeaturesPlugins are always active.
Example:
slurm.conf: NodeFeaturesPlugins=node_features/helpers NodeName=cloud[1-5] ... State=CLOUD Feature=f1,f2,l1 NodeName=cloud[6-10] ... State=CLOUD Feature=f3,f4,l2 helpers.conf: NodeName=cloud[1-5] Feature=f1,f2 Helper=/bin/true NodeName=cloud[6-10] Feature=f3,f4 Helper=/bin/true
Features f1, f2, f3, and f4 are changeable features and are defined on the node lines in the slurm.conf because CLOUD nodes do not register before being allocated. By setting the Helper script to /bin/true, the slurmd's will not report any active features to the controller and the controller will manage all the active features. If the Helper is set to a script that reports the active features, the controller will validate that the reported active features are a super set of the node's active changeable features in the controller. Features l1 and l2 will always be active and can be used as selectable labels.
Hybrid Cluster
Cloud nodes to be acquired on demand can be placed into their own Slurm
partition. This mode of operation can be used to use these nodes only if so
requested by the user. Note that jobs can be submitted to multiple partitions
and will use resources from whichever partition permits faster initiation. A
sample configuration in which nodes are added from the cloud when the
workload exceeds available resources. Users can explicitly request local
resources or resources from the cloud by using the --constraint
option.
Example:
# Excerpt of slurm.conf SelectType=select/cons_tres SelectTypeParameters=CR_CORE_Memory SuspendProgram=/usr/sbin/slurm_suspend ResumeProgram=/usr/sbin/slurm_resume SuspendTime=600 SuspendExcNodes=tux[0-127] TreeWidth=128 NodeName=DEFAULT Sockets=1 CoresPerSocket=4 ThreadsPerCore=2 NodeName=tux[0-127] Weight=1 Feature=local State=UNKNOWN NodeName=ec[0-127] Weight=8 Feature=cloud State=CLOUD PartitionName=debug MaxTime=1:00:00 Nodes=tux[0-32] Default=YES PartitionName=batch MaxTime=8:00:00 Nodes=tux[0-127],ec[0-127]
When SuspendTime is set globally, Slurm attempts to suspend all nodes unless excluded by SuspendExcNodes or SuspendExcParts. It can be tricky to have to remember to add on-premise nodes to the excluded options. By setting the global SuspendTime to INFINITE and configuring SuspendTime on cloud specific partitions, you can avoid having to exclude nodes.
Example:
# Excerpt of slurm.conf SelectType=select/cons_tres SelectTypeParameters=CR_CORE_Memory SuspendProgram=/usr/sbin/slurm_suspend ResumeProgram=/usr/sbin/slurm_resume TreeWidth=128 NodeName=DEFAULT Sockets=1 CoresPerSocket=4 ThreadsPerCore=2 NodeName=tux[0-127] Weight=1 Feature=local State=UNKNOWN NodeName=ec[0-127] Weight=8 Feature=cloud State=CLOUD PartitionName=debug MaxTime=1:00:00 Nodes=tux[0-32] Default=YES PartitionName=batch MaxTime=8:00:00 Nodes=tux[0-127],ec[0-127] PartitionName=cloud Nodes=ec[0-127] SuspendTime=600
Here we have configured a partition with only cloud nodes and defined SuspendTime on that partition. Doing so will allow us to control when those nodes power down without affecting our on-premise nodes, therefore SuspendExcNodes or SuspendExcParts are not needed in this setup.
Cloud Accounting
Information about cloud instances can be stored in the database. This can be done by configuring instance id/type upon slurmd startup or with scontrol update. The node's "extra" field will also be stored in the database.
Configuring cloud information on slurmd startup:
$ slurmd --instance-id=12345 --instance-type=m7g.medium --extra="arbitrary string" . . .
Configuring cloud information with scontrol update:
$ scontrol update nodename=n1 instanceid=12345 instancetype=m7g.medium extra="arbitrary string"
This data can then be seen on the controller with scontrol show node. Past and current data can be seen in the database with sacctmgr show instance, as well as through slurmrestd with the /instance and /instances endpoints.
Showing cloud information on the controller with scontrol:
$ scontrol show nodes n1 | grep "NodeName\|Extra\|Instance" NodeName=n1 Arch=x86_64 CoresPerSocket=4 Extra=arbitrary string InstanceId=12345 InstanceType=m7g.medium
Showing cloud information from the database with sacctmgr:
$ sacctmgr show instance format=nodename,instanceid,instancetype,extra NodeName InstanceId InstanceType Extra --------------- -------------------- -------------------- -------------------- n1 12345 m7g.medium arbitrary string
Showing cloud information from the database with slurmrestd:
$ curl -k -s \
--request GET \
-H X-SLURM-USER-NAME:$(whoami) \
-H X-SLURM-USER-TOKEN:$SLURM_JWT \
-H "Content-Type: application/json" \
--url localhost:8080/slurmdb/v0.0.40/instances \
| jq ".instances"
[
{
"cluster": "c1",
"extra": "arbitrary string",
"instance_id": "12345",
"instance_type": "m7g.medium",
"node_name": "n1",
"time": {
"time_end": 0,
"time_start": 1687213177
}
}
]
Topology
Cloud nodes can have topologies defined statically in the config files, or can be dynamically added to and removed from topologies as described in the Topology Guide.